
现阶段这一系列产品的文章内容都挑着十分经典的,令人眼前一亮的优化算法,今日的堆排序算法便是这其中一个。 最先了解什么叫堆,这里边堆(Heap)并非程序流程中运行内存地区,反而是一种完全二叉树表明的算法设计。 堆具备下述特性
- 是一个完全二叉树
- 堆的每一个结点的值务必高于或等于上下树连接点(大顶堆),或不大于上下树连接点(小顶堆)。
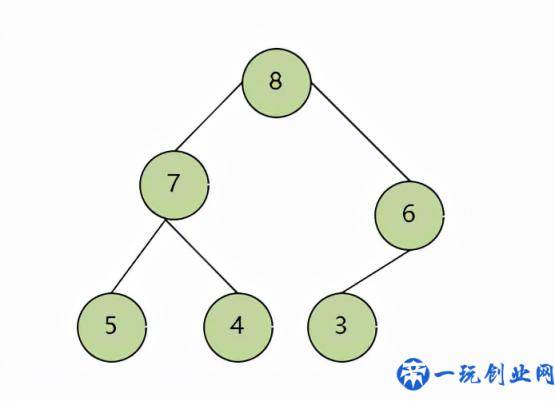
简易表明下,完全二叉树是除开最终一层叶子节点外,别的的连接点都是有2个子树,而叶子节点可以沒有子树,或是仅有左子树。 如下图便是个大顶堆:
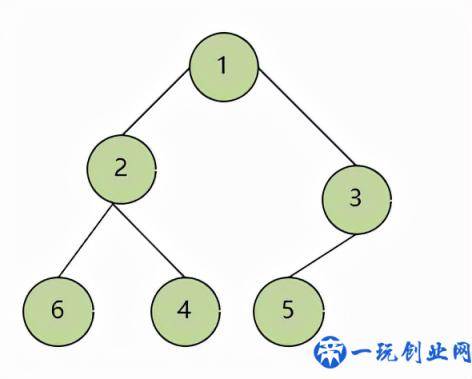
小顶堆
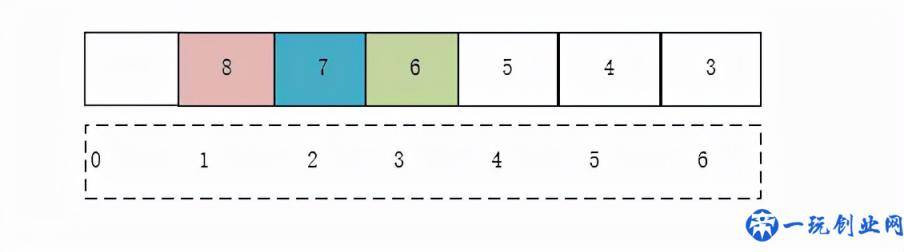
堆储存
堆由于是完全二叉树,特别适合用二维数组储存,图中为大顶堆的储存状况,在其中a[0]不用, a[1]为大顶堆的端点,也就是较大的数据信息,a[12]= 7 为左子树端点,a[12 1]= 6为右子树的顶点,别的连接点状况依次类推。
堆的二种实际操作
向堆插进元素
用图来表明如下所示:
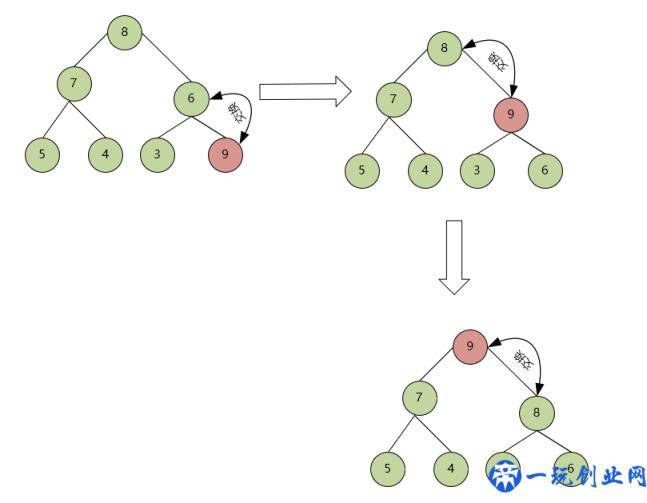
向堆插进元素,先插入到最后一个二维数组元素部位,随后和自身的父节点6较为,因为比6大不符合大顶堆的标准,因此9和6互换,随后9再和堆顶元素8较为,又不符合大顶堆标准,再次互换,最终产生一个大顶堆,这一流程叫堆化。
删掉堆顶元素
针对大顶堆而言,堆顶的元素为最高值,先后删掉堆顶元素并輸出,那麼便是将数据从大向小排序了。
这里边又个方法,便是删掉堆顶元素的情况下,不可以立即删掉,要用堆顶元素和最后一个元素做互换,随后依据堆的特性调节堆,直到符合条件。

详细编码如下所示:
package com.dianneng.lms;
public class TestHeap {
private int [] a;
private int n;
private int count;
public TestHeap(int cap) {
a = new int[cap 1];
n = cap;
count = 0;
}
public void swap(int i,int j) {
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
return;
}
public void print(){
for (int i = 0; i <= count;i ) {
System.out.print(a[i] \"t\");
}
}
public int insert( int v) {
if (count == n) {
System.out.println(\"Heap is full!\");
return -1;
}else {
a[ count] = v;
int i = count;
while (i/2 >0 && a[i] > a[i/2]) {
swap(i,i/2);
i = i/2;
}
}
return 0;
}
public int removeMax() {
if (count == 0) {
return -1;
}
System.out.print(a[1] \"t\");
a[1] = a[count];
--count;
heapify(count,1);
return 0;
}
private void heapify(int n, int i) {
while(true) {
int maxPos = i;
//根据上下子树端点较为得到最大值连接点
if (i*2 <= n && a[i] <a[i*2] ){
maxPos = i*2;
}
if (i*2 1 <= n && a[maxPos] < a[i*2 1]) {
maxPos = i*2 1;
}
//已经是较大的不用互换了
if (maxPos == i) {
break;
}
//必须互换
swap(i,maxPos);
//i偏向待互换的
i = maxPos;
}
}
public static void main(String [] args) {
TestHeap th = new TestHeap(18);
th.insert(8);
th.insert(7);
th.insert(6);
th.insert(5);
th.insert(4);
th.insert(3);
th.print();
System.out.println();
while(th.removeMax() == 0) {
}
}
}
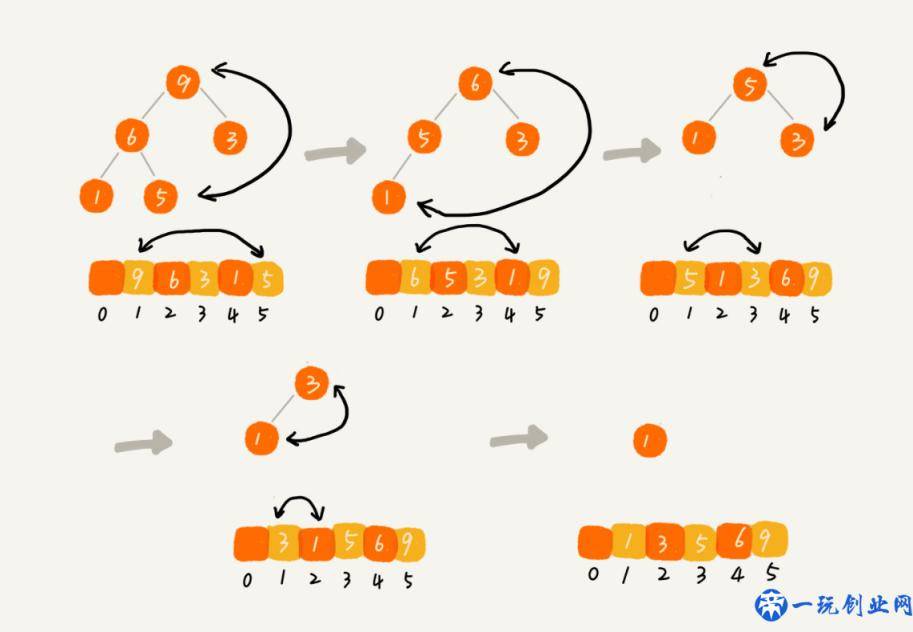
可以运用大顶堆的特点,对要排列的二维数组开展先堆化排列,随后先后互换堆顶元素和最后一个元素,交换后堆化,将堆的尺寸减一,最后那样輸出的是由小到大排列的二维数组。 使用教师的一个图表明:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。

